Overview
TL;DR: LIFT-GS trains a 3D vision-language grounding (3D VLG) model using only 2D rendering supervision: enlarging the training data of 3D VLG from thousands of scenes to billions of images-text pairs.
3D vision-language grounding faces a fundamental data bottleneck: while 2D models train on billions of images, 3D models have access to only thousands of labeled scenes--a six-order-of-magnitude gap that severely limits performance. We introduce LIFT-GS, a practical distillation technique that overcomes this limitation by using differentiable rendering to bridge 3D and 2D supervision. LIFT-GS predicts 3D Gaussian representations from point clouds and uses them to render predicted language-conditioned 3D masks into 2D views, enabling supervision from 2D foundation models (SAM, CLIP, LLaMA) without requiring any 3D annotations. This render-supervised formulation enables end-to-end training of complete encoder-decoder architectures and is inherently model-agnostic. LIFT-GS achieves state-of-the-art results with 25.7\% mAP on open-vocabulary instance segmentation (vs. 20.2\% prior SOTA) and consistent 10-30\% improvements on referential grounding tasks. Remarkably, pretraining effectively multiplies fine-tuning datasets by 2X, demonstrating strong scaling properties that suggest 3D VLG currently operates in a severely data-scarce regime. Project page: https://liftgs.github.io

3D Referential Grounding with LIFT-GS: Using language queries and sparse point clouds as input, LIFT-GS densely reconstructs the scene (in Gaussian Splatting) and grounds the nouns in the 3D scene.
Reconstruction, Recognition, and Reorganization (Three R)
Differentiable rendering can be used with many types of frame-based losses. LIFT-GS demonstrates that it can be used to train a single model for all three R's of computer vision: 3D reconstruction, open-vocabulary recognition, and 3D segmentation (reorganization)—all without any 3D supervision.


Recent works show that even high-resolution image-to-Gaussian models can be trained/finetuned directly from images (L4GM, AVAT3R). LIFT-GS demonstrates that differentiable rendering can be used to train models not just for reconstruction, but also models that predict and ground 3D instance masks using open-vocabulary referring expressions.
Learning from 2D Foundation Models
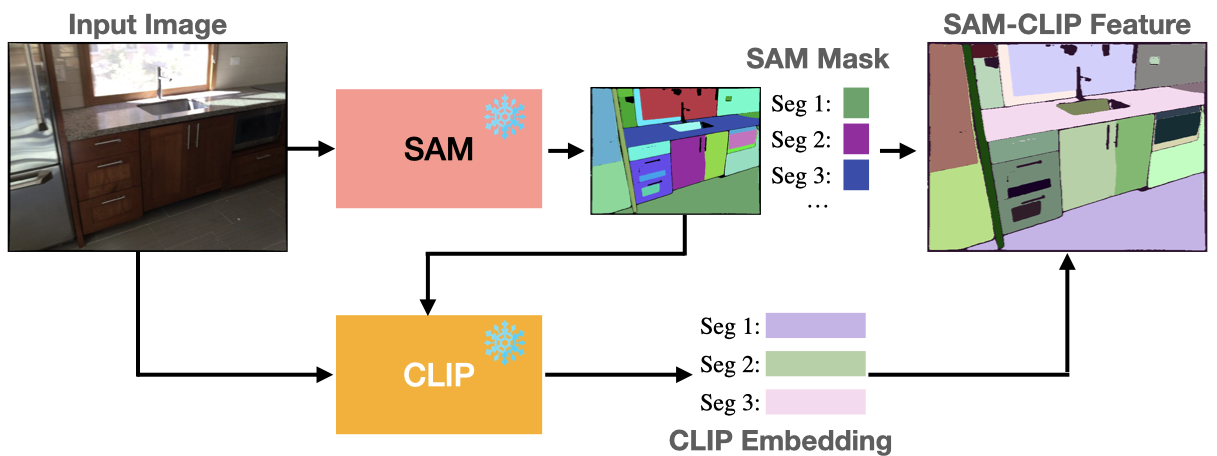
Since 3D mask data is scarce, LIFT-GS leverages 2D foundation-scale models to generate pseudolabels directly on the observed frames. It's these 2D pseudolabels that are used to supervise the 3D model. During training, the model outputs are rendered to features and 2D masks via Gaussian Splatting, and the pseudolabels are used for frame-based supervision. The render-supervised distillation approach is largely agnostic to both architecture and task; in that it can be used to train any 3D models as long as the outputs are renderable to 2D.
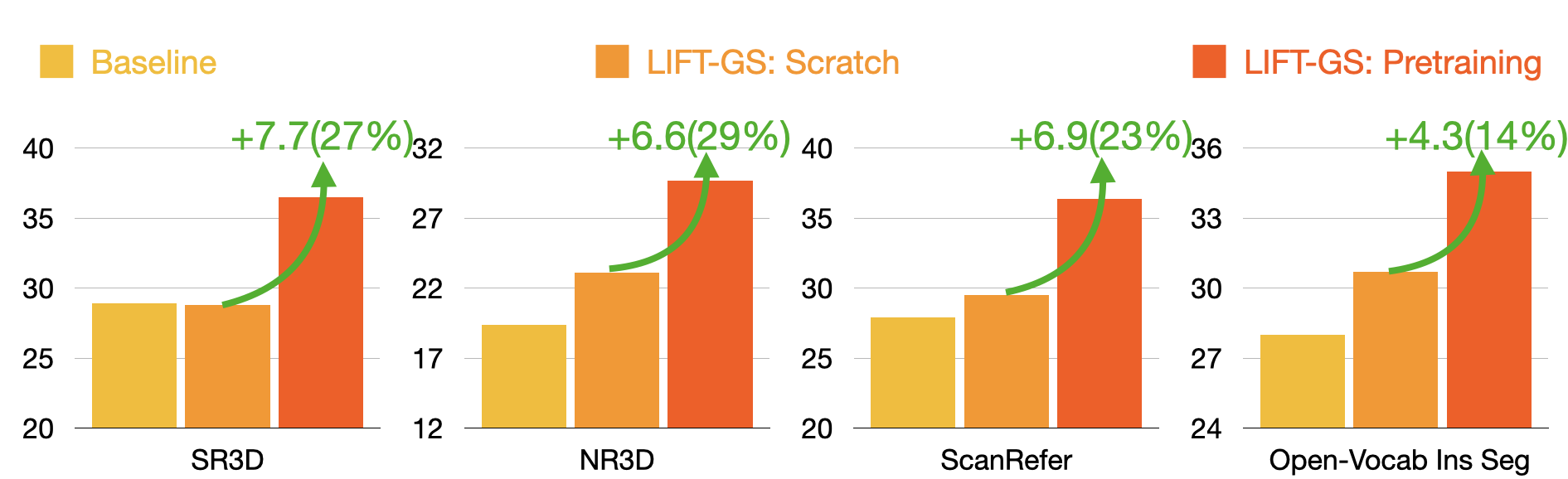
As a Pretraining Pipeline
Finetuning the distilled weights on existing 3D labels, LIFT-GS can significantly outperform both its non-distilled counterpart and also SotA baselines. In the figure below, all pretraining and finetuning is done on the same scenes.
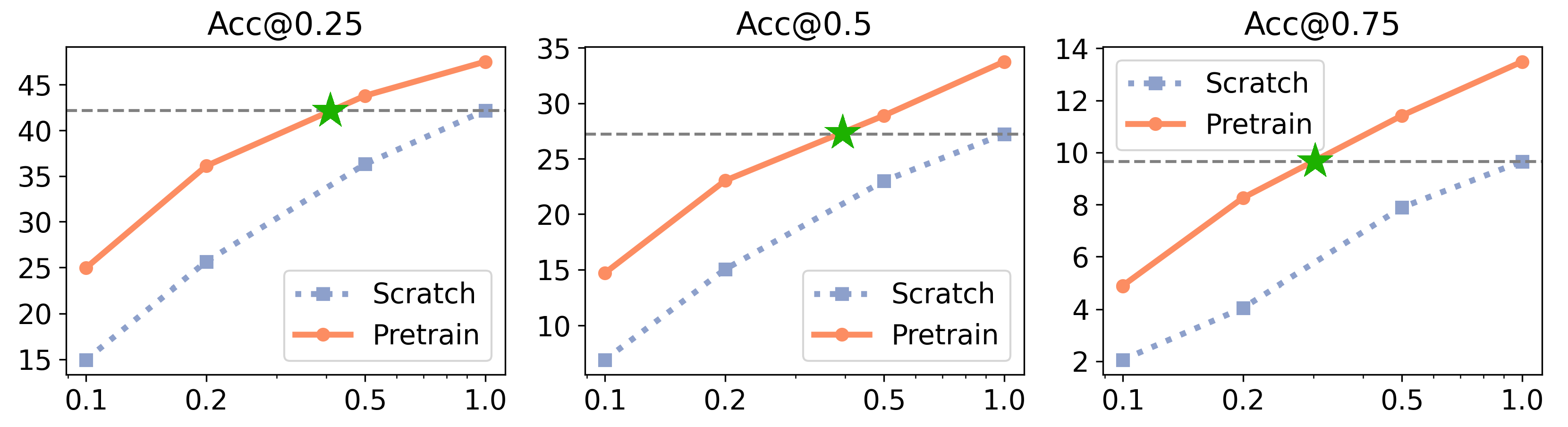
Scaling
LIFT-GS exhibits robust scaling properties.
Our experiments demonstrate a clear "dataset multiplier" effect, where pretraining effectively amplifies the value of finetuning data; consistent with established scaling laws for transfer learning.
Finetuning Data Scaling
Importantly, these gains do not diminish as finetuning data increases to 100%, which indicates that 3D VLG models are currently operating in the severely data-constrained regime.
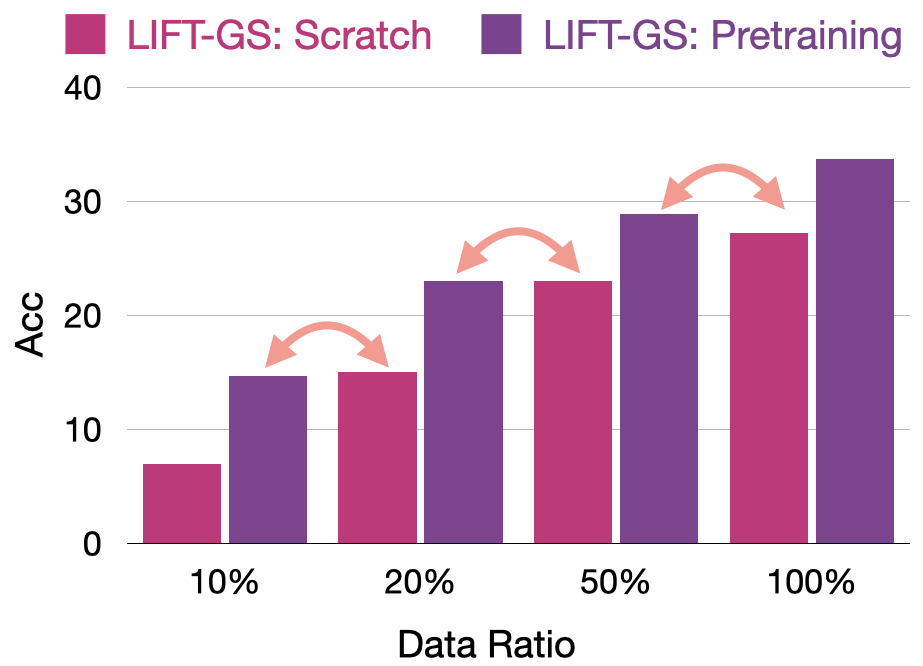 We finetune the pretrained model with different amounts of 3D data,
and find that pretraining effectively multiplies the fine-tuning dataset.
This "dataset multiplier" phenomenon is consistent with established scaling laws for transfer.
We finetune the pretrained model with different amounts of 3D data,
and find that pretraining effectively multiplies the fine-tuning dataset.
This "dataset multiplier" phenomenon is consistent with established scaling laws for transfer.
Pretraining Data Scaling
This suggests that using render-supervision along with foundation-scale image/video data offers a promising approach to scaling 3D vision-language models.
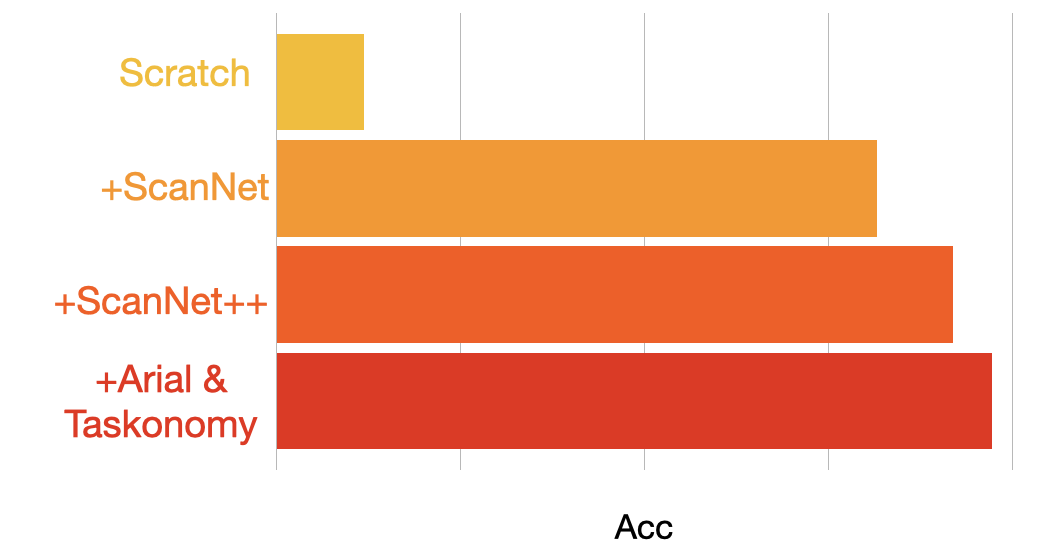 Adding more data to pretraining consistently improves the performance of finetuning.
Adding more data to pretraining consistently improves the performance of finetuning.
Improved Pseudo-Labeling
And our pipeline allows a flexible usage of 2D foundation models and pseudo-labeling strategies.
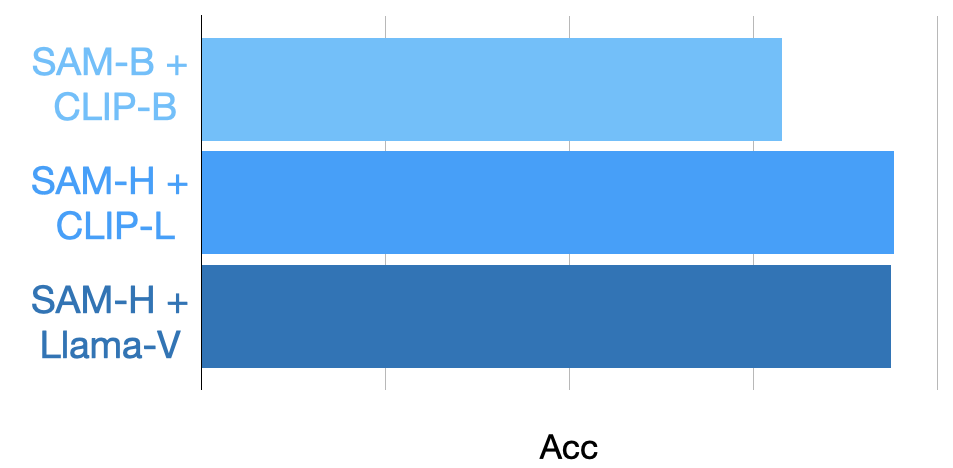 LIFT-GS shows performance gains with larger 2D foundation models and better pseudo-labeling designs.
LIFT-GS shows performance gains with larger 2D foundation models and better pseudo-labeling designs.
BibTeX
@article{liftgs2025,
author = {Cao, Ang and Arnaud, Sergio and Maksymets, Oleksandr and Yang, Jianing and Jain, Ayush and Yenamandra, Sriram and Martin, Ada and Berges, Vincent-Pierre and McVay, Paul and Partsey, Ruslan and Rajeswaran, Aravind and Meier, Franziska and Johnson, Justin and Park, Jeong Joon and Sax, Alexander},
title = {LIFT-GS: Cross-Scene Render-Supervised Distillation for 3D Language Grounding},
year = {2025},
}